
Ngôn ngữ hiển thị:
Ngôn ngữ hiển thị:
Khổ nỗi là nhiều team kỹ thuật vẫn đang cố tự build AI pipeline trong khi AWS đã làm sẵn 90% công việc đó qua Amazon Bedrock. Mình từng mất gần 3 tháng setup một LLM inference cluster tự quản lý — rồi phải bỏ hết khi Bedrock ra bản GA với latency tốt hơn và chi phí rẻ hơn 40%. Bài này tổng hợp những gì mình học được để bạn không mất công lặp lại.

Amazon Bedrock là managed service cho phép bạn gọi các foundation model (FM) từ nhiều nhà cung cấp — Anthropic Claude, Meta Llama, Mistral, Amazon Titan — qua một API duy nhất, không cần setup GPU hay quản lý model weights. Về bản chất, Bedrock giống như một "AI supermarket" mà bạn chỉ trả tiền theo lượng token dùng.
Điều khiến nó phù hợp với doanh nghiệp: data không rời khỏi AWS account của bạn. Với các tổ chức có yêu cầu compliance nghiêm (ngân hàng, y tế, chính phủ), đây là điểm không thể thương lượng — OpenAI hay Google Vertex AI không đảm bảo được điều này ở mức độ tương đương.
Và quan trọng hơn: bạn có thể fine-tune hoặc dùng Bedrock Knowledge Bases để RAG (Retrieval-Augmented Generation) mà không cần tự dựng vector database hay embedding pipeline. Mọi thứ đã có sẵn trong AWS ecosystem.
Bedrock phù hợp nhất khi bạn cần:
Ngược lại, Bedrock không phải lựa chọn tốt nếu bạn cần latency cực thấp (<100ms) cho real-time voice, hoặc cần train custom model từ đầu trên data đặc thù (khi đó SageMaker là công cụ phù hợp hơn).
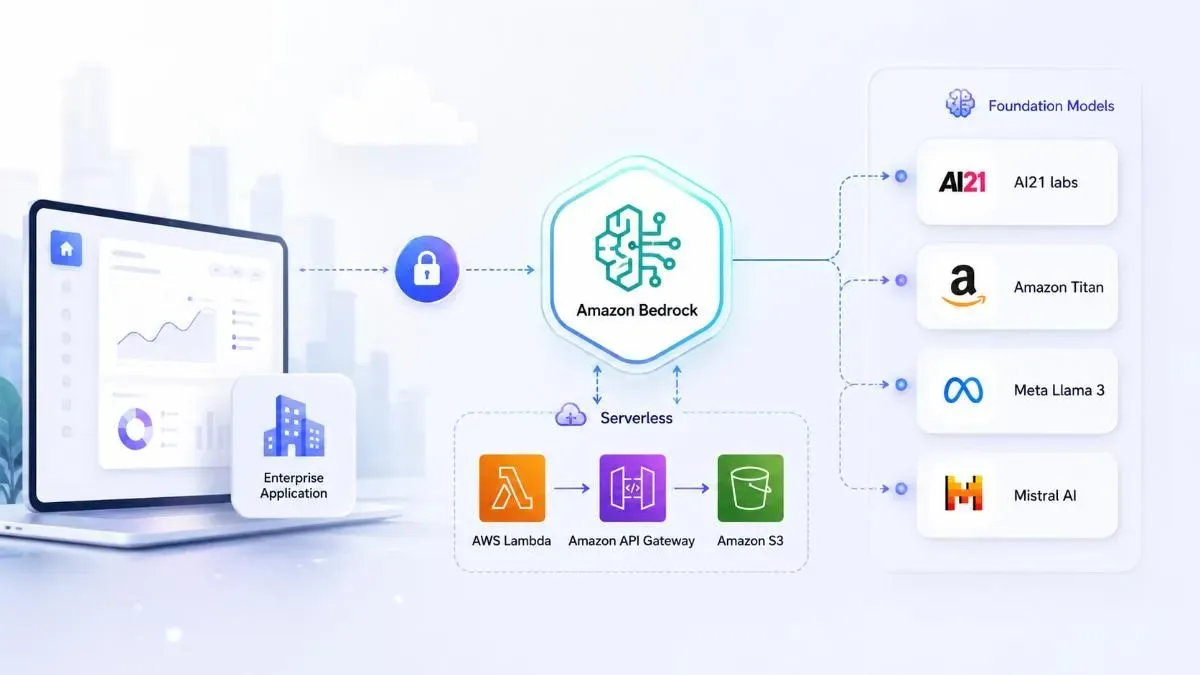
Kiến trúc mình hay dùng nhất: API Gateway → Lambda → Bedrock. Không server nào cần quản lý, scale tự động, và chi phí chỉ tính khi có request.
Bước 1: Setup IAM permissions
Lambda execution role cần policy sau:
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0"
}Chú ý: Resource ARN phải chỉ định đúng model ID và region. Dùng * là antipattern — cho phép invoke bất kỳ model nào, bao gồm cả model đắt tiền.
Bước 2: Gọi Bedrock từ Lambda (Python)
import boto3, json
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
def invoke_claude(prompt: str) -> str:
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [{"role": "user", "content": prompt}]
}
response = bedrock.invoke_model(
modelId="anthropic.claude-3-sonnet-20240229-v1:0",
body=json.dumps(body),
contentType="application/json"
)
result = json.loads(response['body'].read())
return result['content'][0]['text']Mình đặt max_tokens và temperature ở layer config thay vì hard-code trong Lambda — dễ thay đổi mà không cần redeploy.
Bước 3: Streaming response
Với UX chatbot, streaming quan trọng hơn nhiều so với batch. Dùng invoke_model_with_response_stream và stream qua API Gateway WebSocket hoặc Server-Sent Events:
response = bedrock.invoke_model_with_response_stream(
modelId="anthropic.claude-3-sonnet-20240229-v1:0",
body=json.dumps(body)
)
for event in response['body']:
chunk = json.loads(event['chunk']['bytes'])
if chunk['type'] == 'content_block_delta':
yield chunk['delta']['text']Mẹo xương máu: Đặt timeout Lambda tối thiểu 30s khi dùng streaming. Response đầu tiên có thể mất 3–8s tùy model và độ phức tạp của prompt — Lambda timeout mặc định 3s sẽ cut off trước khi token đầu tiên về.
Bedrock Knowledge Bases cho phép bạn index tài liệu từ S3 vào OpenSearch Serverless (vector store managed bởi AWS), rồi query bằng natural language. Setup mất khoảng 20 phút, không cần viết embedding code:
# Query knowledge base
bedrock_agent = boto3.client('bedrock-agent-runtime')
response = bedrock_agent.retrieve_and_generate(
input={"text": "Chính sách hoàn tiền như thế nào?"},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "YOUR_KB_ID",
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0"
}
}
)Thực tế production: đừng dùng Knowledge Bases cho data thay đổi theo giờ — re-indexing mất 5–15 phút tùy kích thước. Với data real-time, vẫn cần tự dựng pipeline với OpenSearch hoặc pgvector.
Bedrock tính phí theo input/output tokens — nghe đơn giản nhưng có vài điểm cần chú ý:
Cross-region inference: AWS có tính năng tự động route request sang region có capacity (cross-region inference). Tiện nhưng giá cao hơn 20–30%. Tắt nếu không cần thiết bằng cách chỉ định inference profile cụ thể.
Provisioned Throughput: Nếu traffic predictable và cao (>50 requests/giây), Provisioned Throughput rẻ hơn on-demand đến 60%. Ngược lại với traffic không đều, on-demand linh hoạt hơn.
Context window: Claude 3 Sonnet có context 200K tokens — nghe nhiều nhưng 200K tokens ≈ 150K words ≈ 300 trang A4. Nếu bạn nhét cả document dài vào prompt thay vì dùng RAG, chi phí sẽ tăng phi tuyến. RAG luôn rẻ hơn full-context với document lớn.
Mình đặt CloudWatch alarm khi spend/ngày vượt ngưỡng và dùng AWS Budgets để tự động throttle nếu chi phí bất thường — hai layer bảo vệ độc lập nhau.
Q: Bedrock có hỗ trợ Vietnamese không?A: Claude 3 và Claude 3.5 trên Bedrock xử lý tiếng Việt tốt, đặc biệt với Sonnet và Opus. Titan và Llama 3.1 cũng hiểu được nhưng output quality thấp hơn đáng kể. Với use case tiếng Việt production, Claude là lựa chọn an toàn nhất hiện tại.
Q: Dữ liệu gửi cho Bedrock có được dùng để train model không?A: Không. AWS cam kết rõ: data bạn gửi qua Bedrock API không được dùng để improve foundation model của third party. Điều này khác với việc bạn dùng Claude.ai trực tiếp (tùy settings). Đọc AWS Data Privacy FAQ để hiểu rõ hơn trước khi triển khai trong môi trường regulated.
Q: Bedrock Agents khác gì so với tự build agent với LangChain?A: Bedrock Agents tích hợp sẵn với Lambda (action groups), Knowledge Bases, và S3 — không cần code orchestration. Nhưng nó kém linh hoạt hơn khi bạn cần custom logic phức tạp hoặc integrate với system ngoài AWS. LangChain/LlamaIndex phù hợp hơn khi bạn cần full control; Bedrock Agents phù hợp khi muốn setup nhanh trong AWS ecosystem.
Nói thật thì ban đầu mình khá skeptical — thêm một layer abstraction nữa trên model API thường là thêm một điểm fail. Nhưng sau khi chạy production với hàng triệu requests, Bedrock đã chứng minh được độ tin cậy. Uptime SLA 99.9%, error rate thấp hơn đáng kể so với gọi thẳng API của Claude hay OpenAI (vì có retry logic built-in), và đặc biệt là không cần lo về data residency với compliance team.
Điểm mình vẫn chưa hài lòng: observability còn hạn chế — CloudWatch metrics của Bedrock chưa đủ granular để debug latency outliers. Phải tự implement distributed tracing với X-Ray mới hiểu được bottleneck thực sự ở đâu. Đây là điều nên làm ngay từ đầu thay vì retrofit sau.
Nếu bạn đang build trên AWS và muốn đưa AI vào sản phẩm trong thời gian ngắn nhất, Bedrock là con đường ngắn nhất — không phải con đường dễ nhất, nhưng là con đường tiết kiệm nhất tính cả chi phí ops về lâu dài.






















































