
Ngôn ngữ hiển thị:
Ngôn ngữ hiển thị:
Query S3 mà không có index — bạn đang trả giá bằng cả tiền lẫn thời gian. Scan 100TB mỗi lần chạy một câu SELECT thì ngay cả sếp cũng không muốn đợi. Mình đã từng ở đúng tình huống đó: pipeline xử lý mất 6 tiếng, báo cáo sáng chưa ra, PM gọi Zalo liên tục. Rồi mình tìm đến cách kết hợp S3 + AWS Glue + Athena — và cái kiến trúc đó đã thay đổi cách team mình làm data từ đó đến nay.

Data Warehouse truyền thống (Redshift, Snowflake) xử lý structured data rất nhanh, nhưng lưu trữ đắt và kém linh hoạt với unstructured data. Data Lake thuần (S3 + raw files) thì rẻ, chứa được mọi thứ, nhưng thiếu schema enforcement và query performance thảm hại khi không tổ chức tốt.
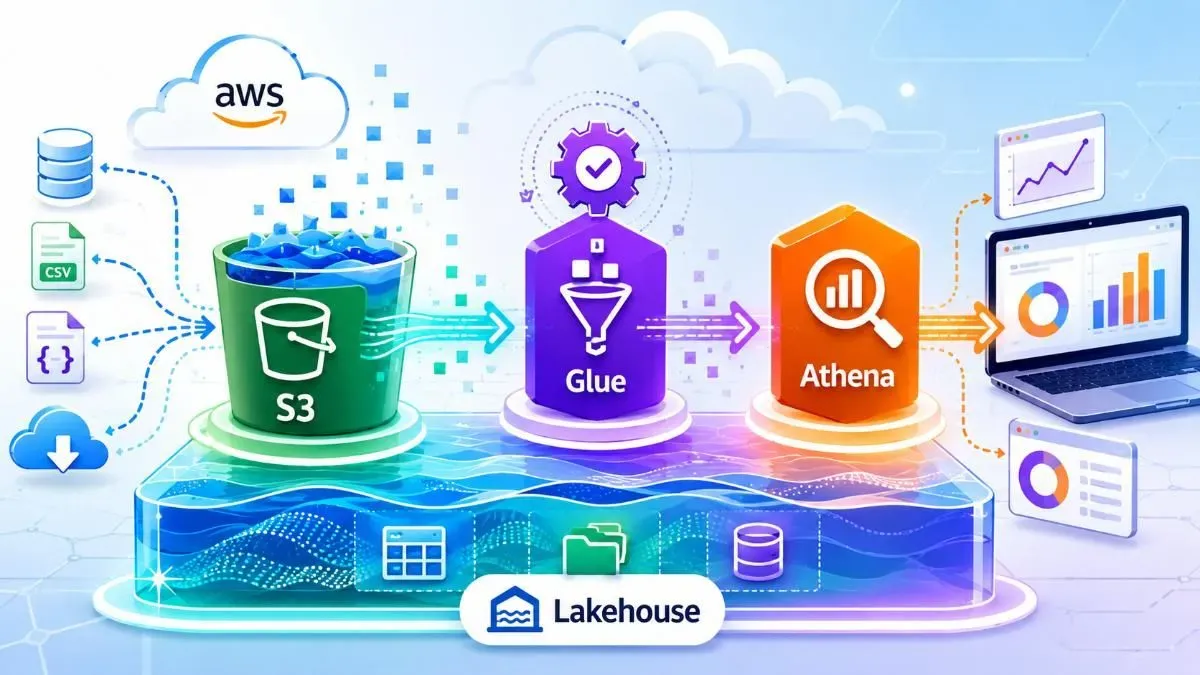
Modern Data Lakehouse ra đời để lấy điểm mạnh của cả hai: lưu trữ rẻ như Lake, query có tổ chức như Warehouse. Trên AWS, kiến trúc này thường được gọi là "S3-centric lakehouse" với ba tầng: Storage (S3), Catalog & Transform (AWS Glue), và Query Engine (Athena). Nếu bạn thêm Apache Iceberg format vào, nó còn hỗ trợ ACID transaction — thứ mà trước đây chỉ Database truyền thống mới có.
Nói thật thì mình thấy nhiều team nhảy thẳng vào Databricks hoặc Snowflake mà không thử option AWS-native này. Chi phí chênh nhau khá rõ, đặc biệt khi data volume còn dưới vài trăm TB và query pattern không quá phức tạp. Với scale vừa phải, S3 + Glue + Athena là bộ ba cực kỳ cost-effective.
Amazon S3 là foundation — không phải chỉ là "ổ cứng trên cloud". S3 hỗ trợ storage class tiering (S3 Intelligent-Tiering tự động chuyển data ít dùng sang storage rẻ hơn), versioning, lifecycle policy, và quan trọng nhất là nó scale vô hạn mà không cần bạn provision gì. Mọi raw data đều phải land ở S3 trước khi được xử lý. Cấu trúc thư mục mình hay dùng:
s3://your-bucket/
├── raw/ # data thô từ source, KHÔNG bao giờ sửa
├── processed/ # sau khi clean, convert sang Parquet
├── curated/ # aggregate sẵn, partition tốt, ready-to-query
└── archive/ # data cũ hơn 1 năm, chuyển sang GlacierNguyên tắc bất biến: raw zone là immutable. Dù transform fail hay logic sai, bạn vẫn có thể replay từ đầu. Xóa raw data là lỗi không thể sửa.
AWS Glue đảm nhận hai vai: ETL engine và Data Catalog. Glue Data Catalog là "schema store" trung tâm — nó biết mỗi folder trong S3 chứa data gì, column nào, type gì, partition ra sao. Khi Athena chạy query, nó lookup Catalog trước để biết cách đọc file. Glue ETL jobs (Python/Spark) xử lý transformation từ raw sang processed và curated.
Một điều ít người biết: Glue Crawler không phải lúc nào cũng cần. Với schema ổn định, mình thường define table thủ công qua Terraform hoặc Athena DDL — nhanh hơn và ít surprise hơn khi Crawler detect nhầm type (ví dụ số điện thoại bị cast thành BIGINT).
Amazon Athena là query engine serverless. Bạn viết SQL chuẩn (Presto/Trino syntax), Athena đọc file trực tiếp từ S3 qua Glue Catalog, trả về kết quả — không cần provision cluster, không cần quản lý server. Chi phí tính theo lượng data scan ($5/TB scanned). Đây là lý do tại sao partitioning và columnar format không phải tùy chọn mà là bắt buộc: partition theo date có thể giảm data scan từ 100% xuống còn 0.1%.
Layer 1 — Ingestion Zone (Raw): Data từ source systems (RDS, Kafka, API REST, file CSV/JSON) được đẩy vào S3 raw zone với format gốc, không transform. Tool phổ biến: Kinesis Data Firehose cho streaming (buffer 128MB/5 phút trước khi ghi), AWS DMS cho database replication, hoặc Lambda trigger khi có file upload.
Layer 2 — Processing Zone (Processed): Glue job chạy theo schedule (EventBridge Scheduler) hoặc trigger (S3 Event Notification), đọc từ raw, áp dụng data quality checks, clean null/duplicate, convert sang Parquet hoặc ORC (columnar format, nén tốt hơn CSV 5-10 lần). Partition theo ingestion date ở layer này.
Layer 3 — Curated Zone: Glue job thứ hai tổng hợp, join với reference data, tính aggregate, tạo ra business-ready tables. Đây là layer mà analyst và BI tool query. Partition theo business date (order_date, event_date) thay vì ingestion date. Format Parquet với compression Snappy là lựa chọn cân bằng tốt giữa nén và query speed.
Layer 4 — Consumption: Athena expose SQL interface. Kết nối với Amazon QuickSight, Apache Superset, Tableau, hoặc bất kỳ BI tool nào qua JDBC/ODBC. Athena Workgroup giúp phân quyền, set quota chi phí, và lưu shared query cho cả team dùng chung.
Mẹo xương máu: Nếu bạn cần UPDATE hoặc DELETE rows trên Lakehouse, hãy dùng Apache Iceberg format cho curated layer. Athena v3 hỗ trợ Iceberg natively với full ACID transaction. Bạn vừa có tính linh hoạt của lake, vừa có data consistency của warehouse — mà không cần Spark cluster thường trực.
Bước 1: Tạo S3 bucket với cấu trúc và lifecycle policy. Bật versioning cho raw zone. Enable S3 Intelligent-Tiering cho archive. Đặt bucket policy block public access — đây là rule không có ngoại lệ. Tạo S3 bucket riêng cho Athena query results.
resource "aws_s3_bucket_lifecycle_configuration" "lakehouse" {
bucket = aws_s3_bucket.main.id
rule {
id = "archive-old-data"
status = "Enabled"
transition {
days = 90
storage_class = "GLACIER_IR"
}
expiration {
days = 365
}
}
}Bước 2: Tạo Glue Data Catalog database và define schema thủ công. Đừng dùng Crawler cho lần đầu — hãy define table bằng DDL trong Athena. Với Parquet file, schema phải khớp chính xác với struct bạn ghi vào.
-- Tạo table trong Athena (tự động đăng ký vào Glue Catalog)
CREATE EXTERNAL TABLE IF NOT EXISTS curated.orders (
order_id STRING,
customer_id STRING,
amount DOUBLE,
status STRING,
created_at TIMESTAMP
)
PARTITIONED BY (year STRING, month STRING, day STRING)
STORED AS PARQUET
TBLPROPERTIES ("parquet.compression"="SNAPPY")
LOCATION 's3://your-bucket/curated/orders/';Bước 3: Viết và deploy Glue ETL job. PySpark script đọc từ raw, transform, ghi Parquet ra processed:
from awsglue.context import GlueContext
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
import sys
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'source_path', 'target_path'])
sc = SparkContext()
glueContext = GlueContext(sc)
# Đọc raw CSV với push_down_predicate để filter partition
raw = glueContext.create_dynamic_frame.from_options(
"s3",
{"paths": [args['source_path']], "recurse": True},
format="csv",
format_options={"withHeader": True, "separator": ","},
push_down_predicate="year='2024' and month='06'"
)
# Ghi Parquet, partition theo date
glueContext.write_dynamic_frame.from_options(
raw, "s3",
{"path": args['target_path'], "partitionKeys": ["year", "month", "day"]},
format="parquet"
)Bước 4: Setup Athena Workgroup. Tạo workgroup riêng cho từng team (data-engineering, analytics, bi-team). Set query result location về S3, enable per-query data scanned limit (ví dụ 50GB/query) để tránh bill shock khi có người viết query SELECT * FROM big_table không có WHERE.
Bước 5: Monitor và tối ưu. CloudWatch Metrics của Glue (NumberOfBytesRead, ExecutionTime) và Athena (DataScannedInBytes, QueryExecutionTime) là hai dashboard bạn cần xem hàng tuần. Đặt CloudWatch Alarm khi monthly Athena cost vượt ngưỡng. Sau 1 tháng vận hành, review lại partition strategy — đôi khi partition theo giờ tốt hơn theo ngày tùy access pattern thực tế.
Small file problem. Athena scan hàng triệu file 1KB chậm hơn rất nhiều so với vài nghìn file 128MB. Nếu dùng Kinesis Firehose, tăng buffer size lên 128MB và buffer interval 300 giây. Nếu đã có nhiều small file, dùng Glue job chạy định kỳ để compact (đọc nhiều file nhỏ, ghi lại thành file lớn).
Partition explosion. Partition theo giờ trong 3 năm = 26,000+ partitions. MSCK REPAIR TABLE sẽ mất hàng tiếng. Solution: dùng Partition Projection trong Athena để auto-generate partition metadata mà không cần scan S3:
-- Thêm vào TBLPROPERTIES khi tạo table
"projection.enabled" = "true",
"projection.year.type" = "integer",
"projection.year.range" = "2022,2030",
"projection.month.type" = "integer",
"projection.month.range" = "1,12",
"projection.month.digits" = "2",
"storage.location.template" = "s3://bucket/curated/orders/${year}/${month}/"Schema evolution trap. Thêm cột mới vào source data thì Parquet file cũ không có cột đó — Athena handle được nếu cột mới nullable. Nhưng nếu bạn đổi type (STRING sang BIGINT), phải re-process toàn bộ data cũ. Rule của mình: chỉ ADD column, không bao giờ RENAME hoặc CHANGE TYPE sau khi đã có data trong production.
Glue job không dùng push_down_predicate. Nếu Glue job đọc cả partition table mà không filter trước, nó load toàn bộ data vào Spark rồi mới filter — tốn RAM và chạy chậm. Bật push_down_predicate để Glue chỉ đọc đúng partition cần thiết, giảm chi phí DPU-hour đáng kể.
Q: Data Lakehouse trên AWS có thể thay thế hoàn toàn Redshift không?A: Phụ thuộc vào use case. Nếu cần query dưới 1 giây với data dưới 100GB, Redshift vẫn nhanh hơn. Với analytical query trên data lớn hơn 1TB và không cần low-latency, Athena + S3 rẻ hơn đáng kể. Nhiều công ty dùng song song: Redshift cho operational reporting cần tốc độ, Athena cho ad-hoc exploration và data science.
Q: AWS Glue có đắt không? Khi nào nên dùng Lambda thay Glue?A: Glue tính phí theo DPU-hour (khoảng $0.44/DPU-hour cho Glue ETL). Job nhỏ 10 phút với 2 DPU chỉ tốn khoảng $0.15/lần chạy. Lambda phù hợp với file nhỏ dưới 256MB và transformation đơn giản. Với GB hoặc TB data, Glue là lựa chọn đúng vì có Spark native và memory lớn hơn nhiều. Glue Flex execution (spot instance) giảm chi phí thêm 30% cho job không cần chạy ngay.
Q: Có nên dùng Apache Iceberg không hay Parquet thường là đủ?A: Parquet thường là đủ cho 80% use case — append-only data, analytics thuần túy. Iceberg cần thiết khi bạn cần UPDATE/DELETE rows (GDPR compliance, data correction), cần time travel để xem data tại thời điểm cụ thể trong quá khứ, hoặc cần schema evolution mượt mà hơn. Iceberg có overhead về metadata management, đừng dùng cho bảng nhỏ hoặc batch đơn giản.
Mình không nói Data Lakehouse trên AWS là perfect. Athena không phải lúc nào cũng nhanh như Redshift với complex join. Glue cũng có quirk riêng — cold start job mất 1-2 phút, schema inference đôi khi sai. Nhưng tỷ lệ chi phí/hiệu năng của bộ ba S3 + Glue + Athena rất khó đánh bại ở scale vừa và lớn.
Điều mình học được sau nhiều lần build rồi rebuild: đừng over-engineer từ đầu. Start với S3 raw/processed/curated + Glue Catalog + Athena. Khi cần ACID transaction, thêm Iceberg. Khi cần real-time ingestion, thêm Kinesis. Khi cần ML feature store, kết nối thêm SageMaker Feature Store. Architecture tốt là thứ bạn có thể mở rộng từng bước — không phải thứ bạn phải rebuild sau 6 tháng vì chọn sai foundation.
Stack này đang giúp team mình xử lý vài chục TB mỗi ngày, với bill hàng tháng dưới $2,000. Nếu bạn đang cân nhắc giữa các lựa chọn, hãy thử pilot với một dataset nhỏ trước — 2 tuần là đủ để thấy nó có phù hợp với bài toán của bạn không.