
Kiến Trúc Amazon EKS: Bảo Mật & Tự Động Mở Rộng
Danh Mục Bài Viết
- 1. Tổng Quan Kiến Trúc EKS Production-Ready
- 2. Bảo Mật EKS: Tư Duy Theo Lớp
- 3. IRSA — Cách Đúng Để Cấp AWS Permission Cho Pod
- 4. Network Policy — Microsegmentation Cho Kubernetes
- 5. Pod Security Standards — Thay Thế PodSecurityPolicy
- 6. Autoscaling Thực Sự: Cluster Autoscaler vs Karpenter
- 7. KEDA — Scale Pod Dựa Trên Business Metrics
- 8. Ổ Gà Thường Gặp Khi Vận Hành EKS
- 9. FAQ
- 10. Đúc Kết
Kubernetes trên AWS nghe có vẻ đơn giản — chạy eksctl create cluster là xong. Khổ nỗi là, cái cluster mặc định đó không nên đụng vào production. Mình đã từng thấy một team mất 3 tiếng debug vì Pod của họ không lên được do thiếu IAM permission, trong khi người khác trong team lại cấp AdministratorAccess cho toàn bộ node để cho nó "chạy đi đã". Cả hai đều là thảm họa theo cách khác nhau. Bài này là những gì mình đúc kết sau nhiều lần vận hành EKS ở môi trường thực tế — tập trung vào bảo mật và autoscaling, hai thứ quyết định cluster của bạn có sống sót qua traffic spike hay không.
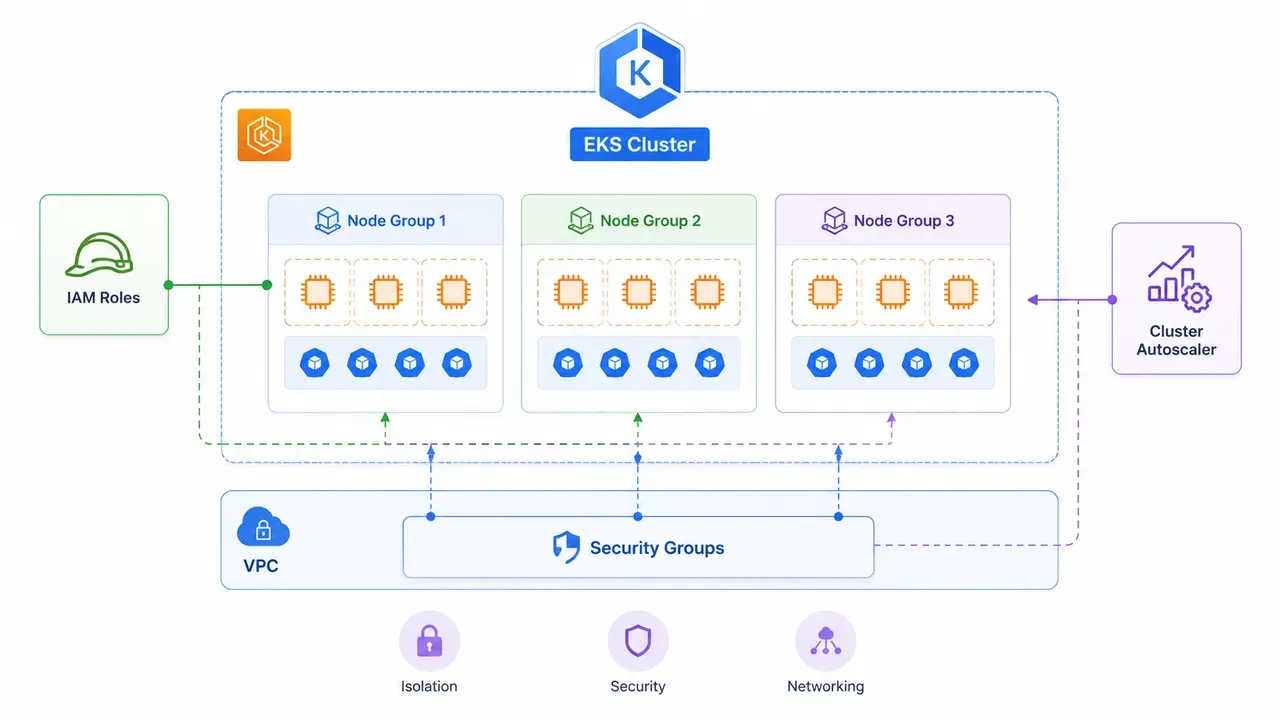
Tổng Quan Kiến Trúc EKS Production-Ready
EKS về bản chất là Kubernetes control plane do AWS quản lý — bạn không truy cập được etcd hay API server node, chỉ interact qua kubectl và AWS API. Điều này có nghĩa là một số quyết định kiến trúc bị "lock" từ phía AWS, nhưng phần còn lại — network, IAM, storage, scaling — hoàn toàn thuộc về bạn.
Một cluster EKS production tối thiểu cần có:
Control Plane — Managed hoàn toàn bởi AWS, spread qua 3 AZ. Bạn chọn Kubernetes version và upgrade schedule.
Node Groups — Có 2 loại chính: Managed Node Groups (AWS tự handle việc provision và drain khi upgrade) và Self-managed nodes (linh hoạt hơn nhưng tốn công bảo trì hơn). Ngoài ra còn Fargate profiles nếu bạn muốn serverless hoàn toàn.
VPC Design — Đây là thứ quan trọng nhất mà nhiều người underestimate. Control plane ENI nằm trong VPC của AWS, worker nodes nằm trong VPC của bạn. Nếu VPC design sai (subnet nhỏ, không đủ IP), cluster sẽ không scale được kể cả khi bạn cấu hình Autoscaler hoàn hảo.
Nguyên tắc: mỗi AZ nên có ít nhất một subnet riêng cho nodes với /24 (256 IP) trở lên. Dùng custom networking cho VPC CNI nếu IP pool đang cạn.
Bảo Mật EKS: Tư Duy Theo Lớp
Bảo mật EKS không phải là một checklist — đó là nhiều lớp bảo vệ chồng lên nhau. Nếu một lớp bị bypass, lớp tiếp theo vẫn còn đó. Mình chia làm 4 lớp chính:
IRSA — Cách Đúng Để Cấp AWS Permission Cho Pod
IAM Roles for Service Accounts (IRSA) là thứ đầu tiên bạn phải hiểu. Trước khi có IRSA, người ta hay cấp IAM policy trực tiếp cho EC2 instance (node), nghĩa là mọi Pod trên node đó đều có quyền như nhau. Đây là lỗ hổng kinh điển.
IRSA hoạt động bằng cách bind IAM role vào Kubernetes Service Account thông qua OIDC provider. Mỗi Pod dùng SA đó sẽ nhận được temporary credentials riêng qua web identity token — không share với Pod khác, không share với node.
# Tạo OIDC provider cho cluster
eksctl utils associate-iam-oidc-provider --cluster my-cluster --approve
# Tạo IAM service account
eksctl create iamserviceaccount --cluster my-cluster --namespace kube-system --name aws-load-balancer-controller --attach-policy-arn arn:aws:iam::ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --approveSau đó trong Pod spec, chỉ cần reference Service Account đó là xong. AWS SDK trong container tự động pick up credentials từ projected volume. Không cần access key, không cần secret hardcode.
Mẹo thực chiến: Luôn enable
AWS_REGIONvàAWS_DEFAULT_REGIONtrong container nếu dùng IRSA — một số SDK cũ không tự detect region từ metadata endpoint.
Network Policy — Microsegmentation Cho Kubernetes
Mặc định, mọi Pod trong cluster đều có thể talk với mọi Pod khác. Không filter, không restrict. Nghĩ mà xem: nếu một Pod bị compromise, attacker có thể lateral move thoải mái qua toàn bộ cluster.
Network Policy là Kubernetes resource để define traffic rules ở layer 3/4. Nhưng để nó hoạt động, bạn cần CNI plugin hỗ trợ — VPC CNI mặc định của EKS không support Network Policy. Có 2 lựa chọn thực tế:
Calico — Open source, mature, support đầy đủ Network Policy và GlobalNetworkPolicy. Cài qua helm chart hoặc operator.
VPC CNI Network Policy Engine — Từ EKS 1.25 trở lên, AWS đã add native Network Policy support vào VPC CNI. Đây là lựa chọn đơn giản hơn nếu bạn không cần features nâng cao của Calico.
# Enable Network Policy trong VPC CNI
kubectl set env daemonset aws-node -n kube-system ENABLE_NETWORK_POLICY=trueRule cơ bản nhất: default-deny all, sau đó mở từng port cần thiết. Đây là Network Policy deny-all cho một namespace:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
namespace: production
spec:
podSelector: {}
policyTypes:
- Ingress
- EgressPod Security Standards — Thay Thế PodSecurityPolicy
PodSecurityPolicy đã bị deprecated từ Kubernetes 1.21 và removed ở 1.25. Thay thế chính thức là Pod Security Standards (PSS) với 3 mức: privileged, baseline, và restricted.
Áp dụng PSS qua namespace label — không cần webhook phức tạp:
kubectl label namespace production pod-security.kubernetes.io/enforce=restricted pod-security.kubernetes.io/warn=restricted pod-security.kubernetes.io/audit=restrictedMode restricted block: container chạy root, privilege escalation, hostPath volumes, host network/pid. Hầu hết workload thông thường chạy được với baseline hoặc restricted nếu bạn set securityContext đúng.
Autoscaling Thực Sự: Cluster Autoscaler vs Karpenter
Đây là phần mà nhiều team hiểu sai. Kubernetes có 3 loại autoscaling khác nhau, và chúng phối hợp với nhau — không thay thế nhau:
HPA (Horizontal Pod Autoscaler) — Scale số lượng Pod dựa trên CPU/memory/custom metrics. Hoạt động ở application layer.
VPA (Vertical Pod Autoscaler) — Adjust resource request/limit của Pod. Ít dùng hơn vì cần restart Pod.
Cluster Autoscaler / Karpenter — Scale số lượng Node. Đây là thứ mình sẽ tập trung.
Cluster Autoscaler (CA) là cách truyền thống — nó watch cho Pending Pods, tìm Node Group phù hợp, trigger Auto Scaling Group scale out. Đơn giản, ổn định, nhưng có điểm yếu: scale out chậm (thường 2-5 phút) và bạn phải pre-define instance type cho từng Node Group.
Karpenter — AWS open-source project (bây giờ là CNCF project), provision node trực tiếp qua EC2 API, không qua ASG. Nhanh hơn đáng kể (dưới 60 giây), chọn instance type tối ưu tự động, support Spot Instances tốt hơn nhiều.
# NodePool Karpenter ví dụ — mix On-Demand và Spot
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64", "arm64"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
disruption:
consolidationPolicy: WhenUnderutilized
consolidateAfter: 30sconsolidateAfter: 30s — Karpenter sẽ terminate node underutilized chỉ sau 30 giây. Rất hữu ích để giảm cost, nhưng phải đảm bảo workload của bạn tolerates disruption (PodDisruptionBudget).
Nói thật thì: nếu cluster mới bắt đầu, dùng Karpenter ngay từ đầu. Nếu đang dùng CA, migration sang Karpenter cần lên kế hoạch cẩn thận — không phải cứ swap là xong.
KEDA — Scale Pod Dựa Trên Business Metrics
HPA chỉ scale theo CPU/memory — thứ thường không phản ánh đúng load thực tế. KEDA (Kubernetes Event-Driven Autoscaling) scale dựa trên external metrics: độ dài SQS queue, lag Kafka consumer, số request đang pending trong RDS, hay bất kỳ metric nào từ Prometheus.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: order-processor-scaler
spec:
scaleTargetRef:
name: order-processor
minReplicaCount: 0 # Scale to zero khi không có message
maxReplicaCount: 50
triggers:
- type: aws-sqs-queue
metadata:
queueURL: https://sqs.ap-northeast-1.amazonaws.com/123456/orders
queueLength: "10" # 10 message/replica
awsRegion: ap-northeast-1
authenticationRef:
name: keda-trigger-auth-awsminReplicaCount: 0 có nghĩa là KEDA có thể scale deployment về 0 replica hoàn toàn khi queue trống — sau đó spin up lại khi có message mới. Đây là cách tiết kiệm cost rất hiệu quả cho batch workload.
Ổ Gà Thường Gặp Khi Vận Hành EKS
1. IP exhaustion trong VPC — EKS VPC CNI mặc định assign một VPC IP cho mỗi Pod. Cluster lớn với nhiều Pod sẽ ăn hết IP của subnet. Fix: enable prefix delegation (ENABLE_PREFIX_DELEGATION=true) để mỗi ENI quản lý được /28 prefix thay vì từng IP đơn lẻ.
2. CoreDNS bottleneck — Mặc định EKS chạy 2 CoreDNS replica. Cluster 100+ node với nhiều microservice sẽ overload CoreDNS. Scale lên dựa trên số node, và enable NodeLocal DNSCache để giảm traffic đến CoreDNS pods.
3. Forgot PodDisruptionBudget khi dùng Karpenter — Karpenter consolidation có thể terminate node đang chạy workload stateful. Không có PDB, deployment có thể về 0 replica trong quá trình consolidation. Luôn define PDB cho critical workloads.
4. aws-auth ConfigMap race condition — Nhiều team dùng Terraform để manage aws-auth, nhưng manual edits và Terraform plan conflict nhau. Giải pháp sạch hơn: dùng EKS Access Entries (GA từ cuối 2023) — quản lý cluster access hoàn toàn qua AWS API, không còn aws-auth ConfigMap nữa.
5. EKS add-on version drift — VPC CNI, CoreDNS, kube-proxy cần được upgrade đồng bộ với Kubernetes version. Bỏ qua điều này dễ gây compatibility issue sau khi nâng cluster version. Enable managed add-ons và set update policy OVERWRITE để AWS handle việc này.
FAQ
Q: Karpenter hay Cluster Autoscaler phù hợp hơn cho môi trường production hiện tại?A: Với cluster mới từ EKS 1.23 trở lên, Karpenter là lựa chọn tốt hơn — nhanh hơn, tiết kiệm cost hơn với Spot Instances, và consolidation tự động giảm node underutilized. Tuy nhiên nếu team chưa quen, CA vẫn hoạt động tốt và ít surprises hơn. Migration từ CA sang Karpenter nên làm theo từng Node Group, không làm all-at-once.
Q: IRSA có hoạt động với EKS Fargate không?A: Có. Fargate nodes tự động mount IRSA credentials nếu Pod dùng Service Account có annotation
eks.amazonaws.com/role-arn. Thực ra với Fargate, IRSA là cách duy nhất để cấp AWS permission vì không có EC2 instance metadata endpoint. Đặc biệt lưu ý: Fargate cần tạo Fargate Profile trước khi schedule Pod vào namespace đó.
Q: Làm thế nào để monitor chi phí EKS theo từng team hoặc namespace?A: Dùng Kubernetes labels và AWS Cost Allocation Tags. Tag EC2 node group với
teamvàenv, sau đó enable những tag này trong AWS Cost Explorer. Với phân bổ chi phí theo namespace chi tiết hơn, Kubecost là công cụ phổ biến nhất — có free tier dùng được cho cluster vừa và nhỏ. OpenCost là alternative open-source nếu bạn không muốn phụ thuộc vendor.
Đúc Kết
EKS không khó — nhưng dễ bị lừa bởi cảm giác "nó đang chạy". Running khác với production-ready. Bảo mật theo lớp (IRSA + Network Policy + Pod Security Standards) và autoscaling đúng cách (Karpenter/CA + KEDA) là nền tảng để cluster thực sự scale và survive. Đừng đợi đến khi có incident mới nghĩ đến những thứ này — lúc đó sẽ là 3 giờ sáng và bạn sẽ ước gì mình đọc bài này sớm hơn.