
CI/CD Pipeline AWS: Chuẩn Hóa CodePipeline và GitOps
Đã từng làm việc với một hệ thống 15 microservices, mỗi service một bộ pipeline riêng — có cái dùng Jenkins, có cái dùng GitHub Actions, có cái thậm chí vẫn deploy tay bằng SSH. Mỗi lần onboard developer mới tốn ít nhất hai tuần chỉ để hiểu "cái service này deploy kiểu gì". Đó là lý do mình quyết định chuẩn hóa toàn bộ bằng AWS CodePipeline kết hợp GitOps — và bài này là kết quả sau 6 tháng vận hành thực tế, bao gồm cả những lần cháy production lúc 2 giờ sáng.
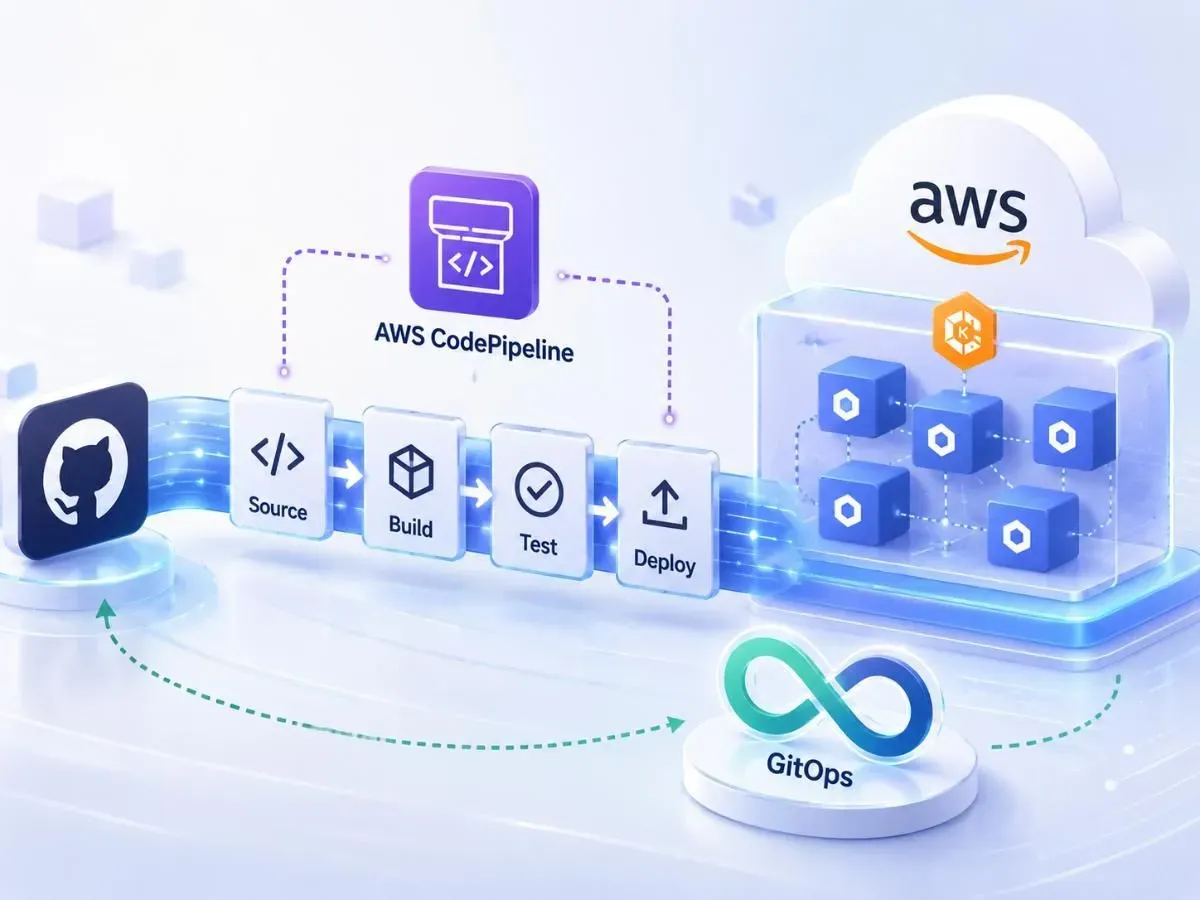
Tổng quan: CI/CD trên AWS — bức tranh tổng thể
Trước khi đi vào chi tiết kỹ thuật, cần thống nhất về định nghĩa. CI (Continuous Integration) là quá trình tự động build và test mỗi khi có commit. CD (Continuous Delivery/Deployment) là tự động đưa code đã pass test lên môi trường target — staging, production, hay bất kỳ environment nào bạn cần.
Trên AWS, bộ công cụ native cho CI/CD gồm: AWS CodePipeline đóng vai trò orchestrator — điều phối toàn bộ workflow từ source đến deploy. AWS CodeBuild là môi trường build và chạy test. Amazon ECR lưu container image. Amazon ECS/EKS chạy container thực tế. Toàn bộ kết nối với nhau qua IAM roles và S3 artifact bucket.
GitOps là một operating model, không phải một công cụ cụ thể. Nguyên tắc cốt lõi: Git là source of truth duy nhất cho cả application state lẫn infrastructure state. Mọi thay đổi đều đi qua Git commit, mọi deployment đều bắt đầu từ một merge vào nhánh chính. Không ai SSH vào server để sửa config trực tiếp — nếu muốn thay đổi, phải commit.
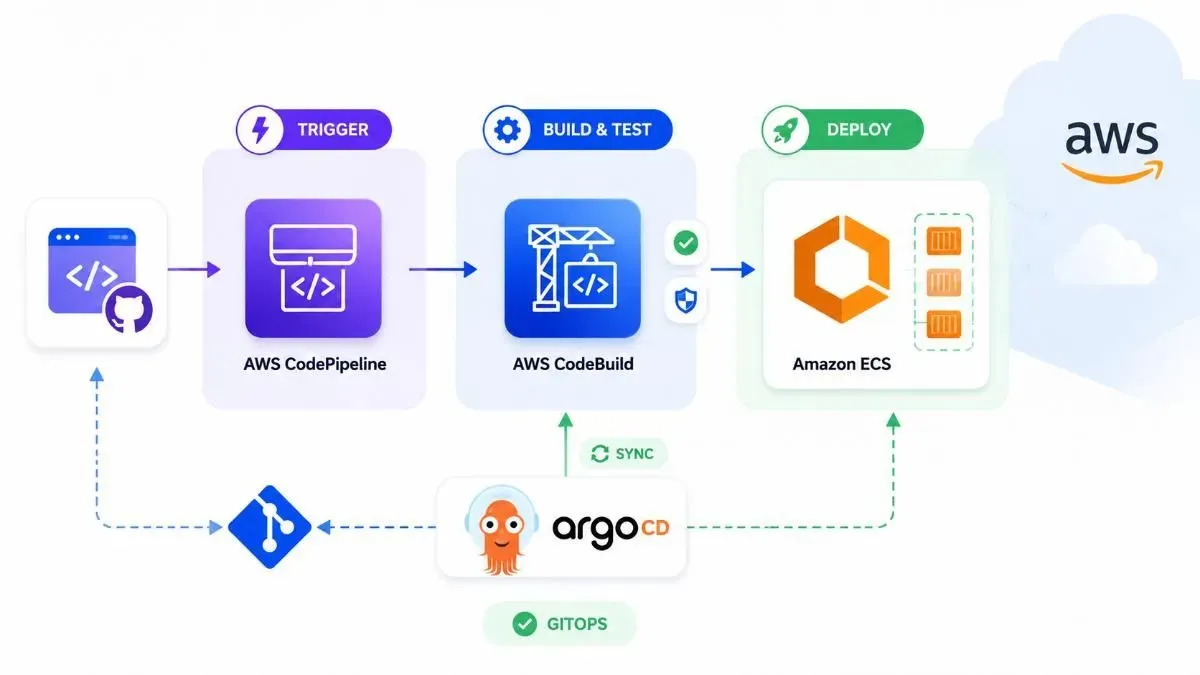
Khi kết hợp CodePipeline với GitOps, pipeline có dạng: Developer push code → CodePipeline trigger tự động → CodeBuild chạy test và build image → Push image lên ECR → Cập nhật image tag trong manifest repo (Git) → ArgoCD hoặc Flux phát hiện thay đổi và sync lên cluster. Điểm khác biệt then chốt: pipeline không deploy trực tiếp lên cluster — nó chỉ cập nhật Git. Phần deploy do GitOps operator xử lý.
Tại sao "mỗi team một kiểu" lại thành vấn đề nghiêm trọng?
Nghe qua thì vô hại. Thực tế thì không. Nói thật thì mình đã thấy pattern này phá team nhiều lần hơn bất kỳ bug kỹ thuật nào.
Vấn đề đầu tiên là onboarding nightmare. Khi join một team mới, hai tuần đầu của mình gần như dành hết để hiểu pipeline — không phải vì code phức tạp, mà vì mỗi service có một cách deploy khác nhau. Một service dùng Makefile, một service dùng bash script inline trong Jenkinsfile, một service thì không ai còn nhớ nó deploy kiểu gì nữa vì người viết đã nghỉ việc từ năm ngoái.
Thứ hai là incident lúc 2 giờ sáng. Khi production down, bạn không có thời gian đọc documentation. Nếu mọi service deploy theo cùng một pattern, on-call engineer có thể rollback trong 2 phút. Nếu mỗi service một kiểu — chúc may mắn. Mình từng mất 45 phút để rollback một service đơn giản chỉ vì không ai nhớ artifact của nó nằm ở đâu.
Thứ ba là security drift. Mỗi pipeline tự manage credential riêng, tự cấu hình IAM role riêng. Sau 6 tháng, không ai còn biết service nào đang có quyền gì. Audit thành ác mộng, và thường khi audit xong thì tìm được vài cái role đang có AdministratorAccess mà không ai nhớ tại sao lại cấp.
Thứ tư là cost không kiểm soát được. Build cost trên AWS CodeBuild tính theo compute time. Pipeline không chuẩn hóa thường có những bước thừa — chạy integration test khi chỉ sửa comment, build image mà không dùng layer cache, giữ artifact lâu hơn cần thiết. Cộng lại thành một khoản đáng kể mỗi tháng.
Kiến trúc đề xuất: Ba tầng pipeline
Sau nhiều lần thử và sai, mình đúc kết thành kiến trúc 3 tầng như sau.
Tầng 1 — Application Pipeline (mỗi service có một pipeline riêng): Source thay đổi → CodePipeline trigger → CodeBuild chạy unit test → CodeBuild build và push image lên ECR → Cập nhật image tag trong manifest repo. Tầng này hoàn toàn tự động, không cần human approval.
Tầng 2 — GitOps Sync (mỗi environment): Khi manifest repo thay đổi, ArgoCD hoặc Flux phát hiện và sync lên cluster tương ứng. Dev environment auto-sync, production cần Pull Request được approve mới merge.
Tầng 3 — Infrastructure Pipeline (shared, cho Terraform hoặc CDK): Thay đổi infrastructure code → CodePipeline → Plan → Manual Approval → Apply. Tầng này luôn có manual approval gate trước production.
Điểm mấu chốt của kiến trúc này: Application pipeline không bao giờ deploy trực tiếp lên cluster. Nó chỉ cập nhật một file YAML trong Git. GitOps operator làm phần còn lại. Kết quả là Git history của manifest repo trở thành audit log hoàn hảo — bạn biết chính xác image nào đang chạy ở đâu, ai approve commit đó, và khi nào.
Hướng dẫn triển khai từng bước
Bước 1: Chuẩn bị IAM Role cho CodeBuild
Nguyên tắc bắt buộc: least privilege. Đừng dùng AdministratorAccess cho CodeBuild role, dù rất tiện. Đây là policy tối thiểu mình dùng:
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:PutImage",
"ecr:InitiateLayerUpload",
"ecr:UploadLayerPart",
"ecr:CompleteLayerUpload",
"s3:GetObject",
"s3:PutObject",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}Mình đã từng gặp incident mà CodeBuild role có quyền xóa ECS cluster. Không phải cố tình — nhưng một bug trong pipeline script đã trigger lệnh xóa nhầm. Từ đó mình cẩn thận hơn rất nhiều với IAM policy.
Bước 2: Cấu trúc buildspec.yml chuẩn hóa
File buildspec.yml là trái tim của CodeBuild stage. Mình chuẩn hóa thành 4 phase cho tất cả services:
version: 0.2
phases:
install:
runtime-versions:
python: 3.11
commands:
- pip install -r requirements-test.txt --quiet
pre_build:
commands:
- aws ecr get-login-password --region $AWS_DEFAULT_REGION | docker login --username AWS --password-stdin $ECR_REPO
- IMAGE_TAG=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c1-8)
- docker pull $ECR_REPO:latest || true
build:
commands:
- pytest tests/unit/ -q
- docker build --cache-from $ECR_REPO:latest -t $ECR_REPO:$IMAGE_TAG -t $ECR_REPO:latest .
- docker push $ECR_REPO:$IMAGE_TAG
- docker push $ECR_REPO:latest
post_build:
commands:
- sed -i "s|IMAGE_PLACEHOLDER|$ECR_REPO:$IMAGE_TAG|g" manifests/deployment.yaml
- git -C manifests add . && git -C manifests commit -m "deploy: $IMAGE_TAG" && git -C manifests pushChú ý --cache-from $ECR_REPO:latest. Đây là một trong những optimization quan trọng nhất — reuse layer cache từ image trước giúp giảm build time từ 8 phút xuống còn 90 giây cho service Python điển hình. Tiết kiệm đáng kể trên CodeBuild cost.
Mẹo xương máu: Đặt
|| truesau lệnhdocker pullđể pipeline không fail khi ECR repo chưa có image nào — thường xảy ra lần build đầu tiên của service mới.
Bước 3: Cấu hình ArgoCD Application
Sau khi cài ArgoCD vào cluster (kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml), tạo Application resource cho mỗi service:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: payment-service
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/your-org/manifests
targetRevision: HEAD
path: apps/payment-service/overlays/production
destination:
server: https://kubernetes.default.svc
namespace: payment
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=trueselfHeal: true là cài đặt quan trọng nhất — nếu ai đó thay đổi trực tiếp trên cluster mà không qua Git, ArgoCD sẽ tự revert về trạng thái trong Git trong vòng vài phút. Đây là enforce của GitOps principle.
Bước 4: Environment promotion với Kustomize
Thay vì dùng Helm values file riêng cho từng environment, mình dùng Kustomize overlays:
manifests/
apps/
payment-service/
base/ # config chung
deployment.yaml
service.yaml
overlays/
dev/ # chỉ override image tag + replicas nhỏ
staging/
production/ # override image tag + replicas lớn + resource limits cao hơnMỗi overlay chỉ cần override những gì khác với base. Khi promote từ staging sang production, chỉ update image tag trong overlays/production/kustomization.yaml và merge Pull Request. Không có staging config nào lọt vào production ngoài ý muốn.
Ổ gà thường gặp — và cách mình đã vấp phải
Ổ gà #1: Credential drift. Một developer hardcode AWS credentials vào buildspec.yml "tạm thời" để test nhanh. Ba tháng sau, credentials đó rotate nhưng không ai nhớ còn nằm trong pipeline. Build bắt đầu fail ở stage deploy và team mất nửa ngày để tìm ra nguyên nhân. Giải pháp: bắt buộc dùng CodeBuild environment variables kết hợp AWS Secrets Manager. Audit định kỳ bằng cách scan tất cả buildspec files trong repo tìm pattern access key.
Ổ gà #2: Artifact store phình to. S3 bucket dùng làm artifact store của CodePipeline tích lũy artifact theo thời gian mà không ai để ý. Một dự án sau 18 tháng, bucket chiếm hơn 600GB và tốn $15/ngày chỉ để lưu artifact cũ không ai dùng. Giải pháp đơn giản: đặt S3 Lifecycle policy xóa objects cũ hơn 30 ngày. Thiết lập một lần, quên đi, tiết kiệm vài trăm đô mỗi năm.
Ổ gà #3: Race condition khi nhiều commit liên tiếp. Developer push liên tục trong 5 phút, 4 pipeline execution chạy cùng lúc. Execution sau override artifact của execution trước, kết quả deploy lên production là một image không khớp với commit nào đang trong staging. Giải pháp: bật PipelineExecutionMode: SUPERSEDED trong CodePipeline — execution mới tự động cancel execution cũ đang chạy.
Ổ gà #4: ArgoCD OutOfSync im lặng. ArgoCD có health status, nhưng nếu không setup alerting, team sẽ không biết khi nào app đang OutOfSync — đặc biệt là trên production. Giải pháp: cấu hình ArgoCD notifications connect với Slack hoặc PagerDuty cho mọi sync failure trên production environment.
FAQ
Q: CodePipeline hay GitHub Actions — chọn cái nào cho AWS workload?A: Nếu team đã all-in AWS và cần tight integration với IAM, ECR, ECS/EKS — CodePipeline native hơn và không cần manage runner. GitHub Actions linh hoạt hơn, có marketplace rộng, và free cho public repo, nhưng cần xử lý OIDC authentication với AWS cẩn thận hơn. Mình dùng CodePipeline cho production workload trên AWS, GitHub Actions cho side project cá nhân.
Q: GitOps có dùng được với ECS không, hay chỉ dành cho Kubernetes?A: ECS dùng được, nhưng ecosystem GitOps cho ECS còn non hơn Kubernetes. Với ECS, bạn có thể dùng CodePipeline update ECS task definition và trigger redeployment khi manifest repo thay đổi — về cơ bản vẫn đạt được GitOps principle. Nếu muốn native hơn, migrate sang EKS để tận dụng đầy đủ ArgoCD/Flux ecosystem.
Q: Rollback nhanh nhất khi production có vấn đề là làm thế nào?A: Với GitOps, rollback là một Git operation thuần túy: tạo commit revert image tag về phiên bản trước, merge vào main. ArgoCD sẽ sync trong 30-90 giây. Nếu cần nhanh hơn nữa, dùng CLI:
argocd app rollback. Thực tế mình đã rollback trong 45 giây kể từ lúc nhận alert. So sánh với rollback thủ công qua ECS console: thường mất 5-10 phút và hay bị miss bước nào đó khi đang panic.--revision
Q: Khi nào nên thêm Manual Approval stage?A: Luôn luôn trước production. Optional trước staging tùy mức độ tin tưởng vào test suite. Manual Approval trong CodePipeline gửi SNS notification và chờ human action — integrate với Slack để reviewer nhận thông báo và approve/reject ngay trong Slack mà không cần vào console AWS.
Đúc kết sau 6 tháng vận hành
Chuẩn hóa CI/CD không phải là việc làm một lần rồi xong. Nó là hành trình liên tục — cải thiện build time, refine security posture, tối ưu cost, và cập nhật theo sự thay đổi của infrastructure.
Nhưng điểm khởi đầu thì rõ ràng: chọn một pattern, implement cho 2-3 service đầu tiên, học từ sai lầm, rồi roll out cho phần còn lại. Đừng cố perfect ngay từ đầu — pipeline "đủ tốt và chạy ổn định" còn có giá trị hơn nhiều so với pipeline "hoàn hảo trên giấy nhưng chưa deploy được".
Nghĩ mà xem: mỗi ngày team vẫn đang dùng pipeline chắp vá là một ngày cộng thêm technical debt, một ngày tăng nguy cơ incident, một ngày developer mới phải học từ đầu. Chi phí của sự trì hoãn cao hơn nhiều so với 2-3 sprint đầu tư để chuẩn hóa.
Nếu bạn đang bắt đầu từ zero: implement CodePipeline cho service đơn giản nhất trước. Sau khi có một pipeline chạy ổn, clone template đó và điều chỉnh cho service kế tiếp. Sau 3-4 service, bạn sẽ có một template chuẩn mà cả team đều hiểu — và đó là nền tảng cho mọi thứ còn lại.